

One of the main features of Sitecore Search is the ability to index and display multi-locale content. However, adding these items to our Sitecore Search instance could be tricky depending on how our site exposes the different language URLs of our pages.
In the following example, I put together some pointers that might help you correctly index all the different language versions of your pages.
If your sitemap has URLs for each language version, you are in luck
As we learned in our previous post, Sitecore Search can crawl all the URLs in our sitemap and add them to our source. If our sitemap has all the URLs for each language version, our source will be able to go to each URL and add them to our dashboard.
However, there’s an important change that we have to make each time crawl these pages:
Different language versions of the same page must have the same ID
It’s very important to make sure that our crawler assigns the same ID to the different language versions of the same page.
For instance:
- www.abc.com/en-us/test
- www.abc.com/ja-jp/test
- www.abc.com/zh-cn/test
While these 3 pages have different URLs, they are just different language versions of the same page. In Sitecore Search terms, they are the same item but with different locales. For this reason, it’s important we assign them the same ID. We can do this by overwriting the item ID in our document extractor code. For example:
id': $('link[rel=canonical]').attr('href').replace(/\/(en-us|ja-jp|zh-cn)/g, '').replaceAll(/[^a-zA-Z\d_-]/g, "_")In this code, we are taking the page’s canonical URL, removing the language code, and replacing any special characters with underscores to generate our unique ID (www_abc_com__test)\
Configuring our Locale Extractor
Now, you might be wondering: if we are assigning them the same ID, how does Sitecore Search differentiate the different URLs as locales of the same page? Fear not, we have an answer for this 😉
Head into your source configuration and click on “Locale Extractors”:

Here, we are able to add Javascript code that will tell Sitecore Search which version of the page is scanning. We do so by reading the request URL, reading the language code from it, and returning the corresponding language. For instance:
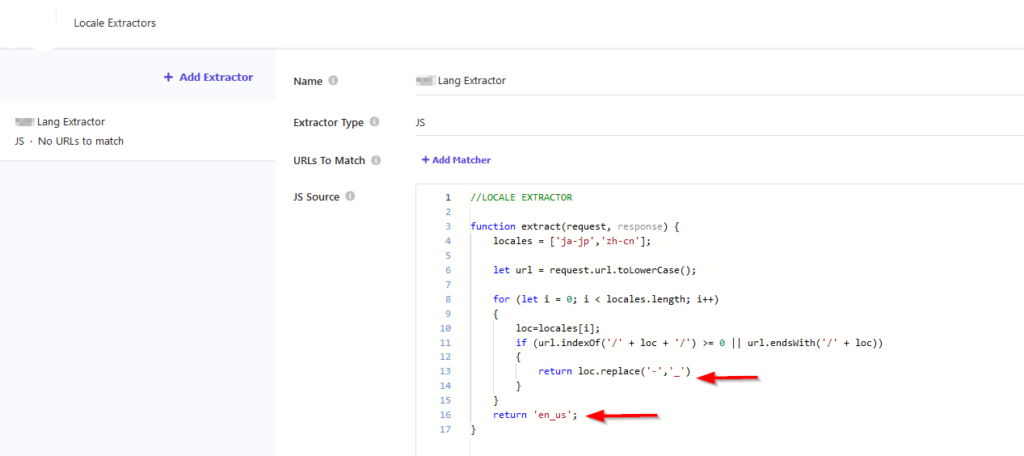
In this example, we are reading the language the language code from the URL (Japanese or Chinese), or in case any of these codes are missing, we are defaulting to English. Then we are retuning the corresponding language codes for these languages.
This tells Sitecore Search to which language the crawled page corresponds.
Help! My sitemap doesn’t contain URLs for each language version
Finally, you might run into a scenario where your sitemap might not contain all the different language URLs, and therefore, your source won’t scan them. 😞
This could probably happen because the site is using a sitemap module that might not support this feature or we might not have access to the code that generates the sitemap.
This is where Sitecore Search’s “Request Extractors” come in handy. This feature allows us to create additional lists of URLs that our crawler can crawl.
In the following example, our sitemap contains a list of URLs for pages in English (that lack a language code in the URL). So, we are going to configure a Request Extractor to generate additional URLs for the other languages on the site:
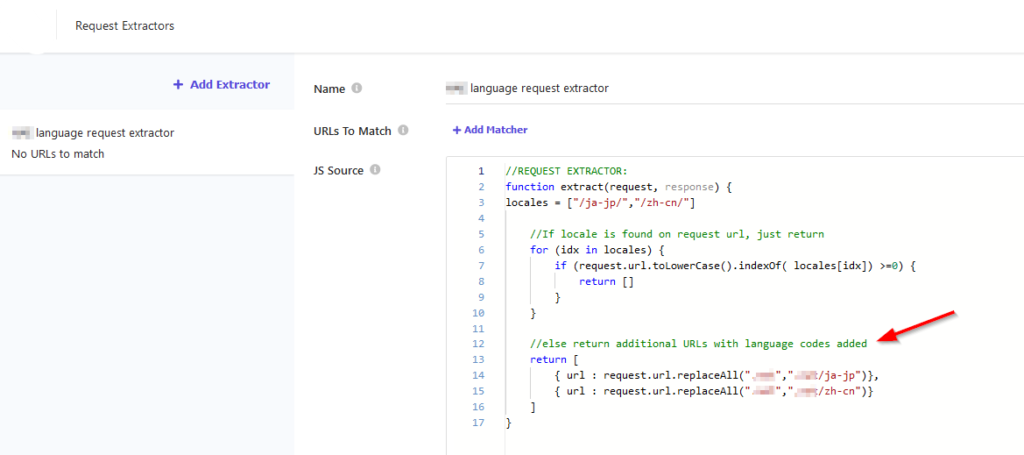
In this example, if no language code is found on the URL, we are going to return additional URLs that contain the language codes of our additional languages 🎉
Final Thoughts
While every site is different, Sitecore Search provides us with the tools to adapt to our needs. I hope these pointers are helpful the next time you need to work with different languages in your Sitecore Search implementation 🤓